Method
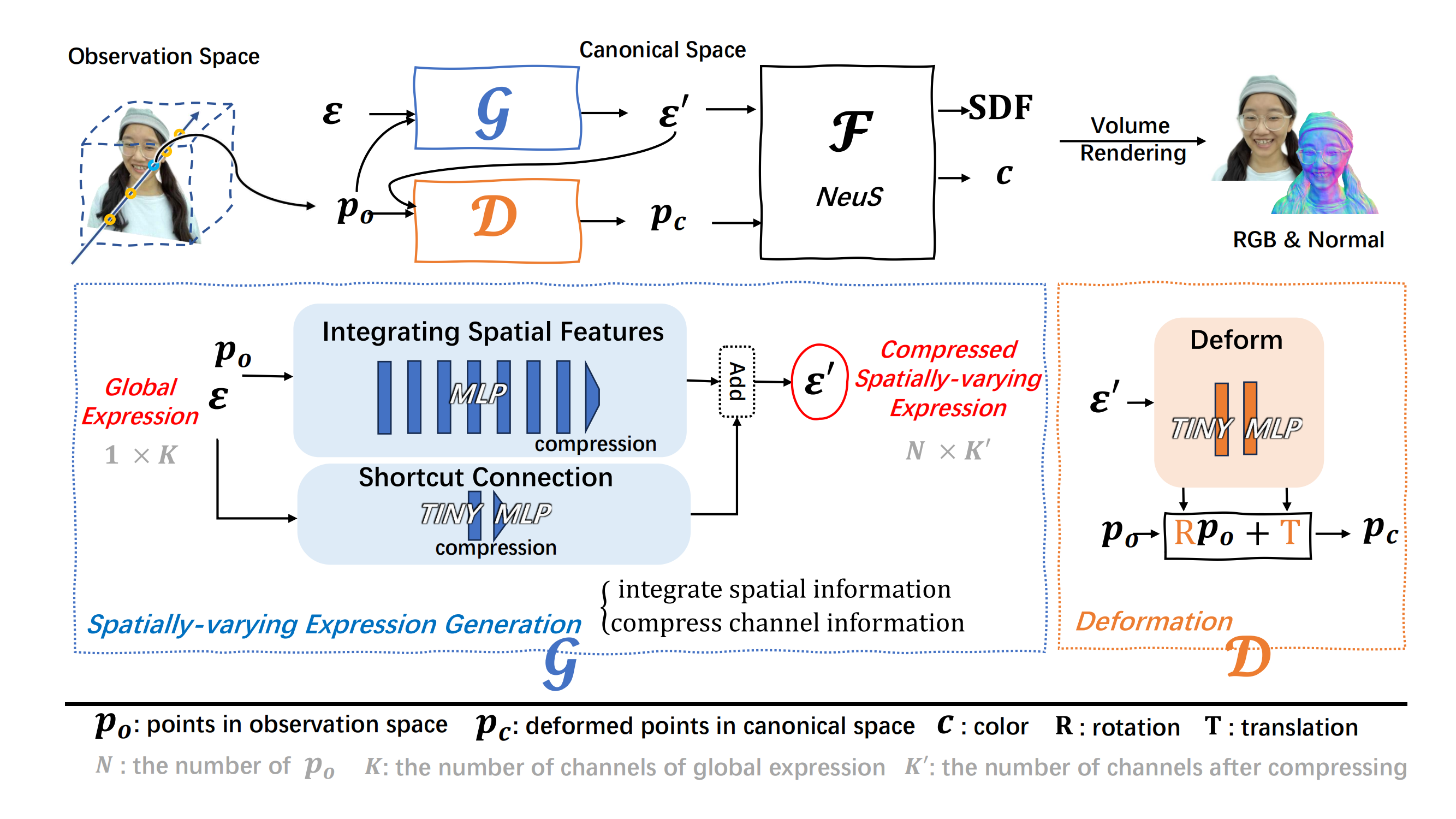
Given a portrait video, We first track the global expression parameters ϵ using 3DMM. After the pre-processing, given the sampled 3D points po in observation space, we apply the generation network G to extend the global expression parameters ϵ with the spatial positional features of each position po in 3D space. Then, through a deformation network D, we transform po from the observation space to the pc in the canonical space conditioned on ϵ'. Subsequently, we use ϵ' conditioned NeuS to predict the SDF values and color c corresponding to pc. Finally, we obtain the rendered RGB image and normal using volumetric rendering.