
🤔 About-me
I earned my Master’s degree in Artificial Intelligence from Tsinghua University  , where I conducted research under the supervision of Prof. Haoqian Wang and collaborated closely with Prof. Yebin Liu on 3DV & Human Avatar Reconstruction. Prior to this, I completed my B.Eng. in Measurement and Control Technology & Instruments at Southeast University
, where I conducted research under the supervision of Prof. Haoqian Wang and collaborated closely with Prof. Yebin Liu on 3DV & Human Avatar Reconstruction. Prior to this, I completed my B.Eng. in Measurement and Control Technology & Instruments at Southeast University  . During my graduate studies, I also had the privilege of visiting Harvard University
. During my graduate studies, I also had the privilege of visiting Harvard University  as a research intern, working with Prof. Hanspeter Pfister on computer graphics.
as a research intern, working with Prof. Hanspeter Pfister on computer graphics.
I am currently an Researcher at ByteDance Seed  , focusing on cutting-edge challenges in perception, generation, and world model.
, focusing on cutting-edge challenges in perception, generation, and world model.
![]()
I am actively recruiting research interns to collaborate on:
📌 3D Scene Perception.
📌 3D Content Creation.
📌 World Model.
If you are seeking any form of academic cooperation, please feel free to email me at qinminghan1999@gmail.com.
🔥 News
- 2025.09: 🎉🎉 3 paper accepted to NeurIPS 2025 !!!
- 2025.07: 🎉🎉 1 paper accepted to ACM MM 2025 !!!
- 2025.06: 🎉🎉 2 paper accepted to ICCV 2025 !!!
- 2025.06: 🎉🎉 NOVA3D has been selected as ICME 2025 Bestpaper Candidate!!!
- 2025.02: 🎉🎉 2 paper accepted to CVPR 2025 !!!
More News
- *2024.09*: 🎉🎉 1 paper accepted to NeurIPS 2024 !!! - *2024.07*: 🎉🎉 1 paper accepted to ACM MM 2024 !!! - *2024.02*: 🎉🎉 2 paper accepted to ECCV 2024 !!! - *2024.02*: 🎉🎉 LangSplat has been selected as CVPR 2024 Highlight !!! - *2024.02*: 🎉🎉 1 paper accepted to CVPR 2024 !!! - *2023.11*: 🎉🎉 1 paper accepted to AAAI 2024 !!!📝 Publications
Vision-Language 3D Perception

LangSplat: 3D Language Gaussian Splatting
Minghan Qin*, Wanhua Li*†, Jiawei Zhou*, Haoqian Wang†, Hanspeter Pfister

- We introduces LangSplat, which constructs a 3D language field that enables precise and efficient open-vocabulary querying within 3D spaces.
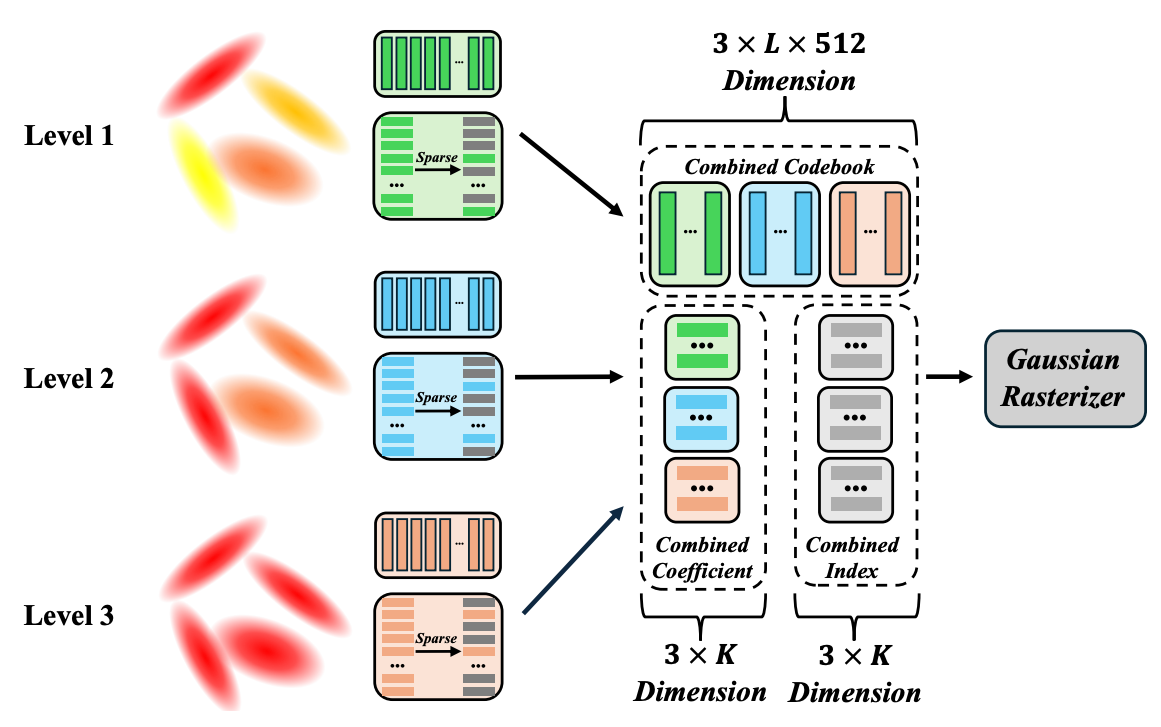
LangSplatV2: High-dimensional 3D Language Gaussian Splatting with 450+ FPS
Wanhua Li*, Yujie Zhao*, Minghan Qin*, Yang Liu, Yuanhao Cai, Chuang Gan, Hanspeter Pfister

- We present LangSplatV2, which achieves high-dimensional feature splatting at 476.2 FPS and 3D open-vocabulary text querying at 384.6 FPS for high-resolution images.

4D LangSplat: 4D Language Gaussian Splatting via Multimodal Large Language Models
Wanhua Li*, Renping Zhou*, Jiawei Zhou, Yingwei Song, Johannes Herter, Minghan Qin, Gao Huang, Hanspeter Pfister
- We present 4D LangSplat, an approach to constructing a dynamic 4D language field in evolving scenes, leveraging Multimodal Large Language Models.
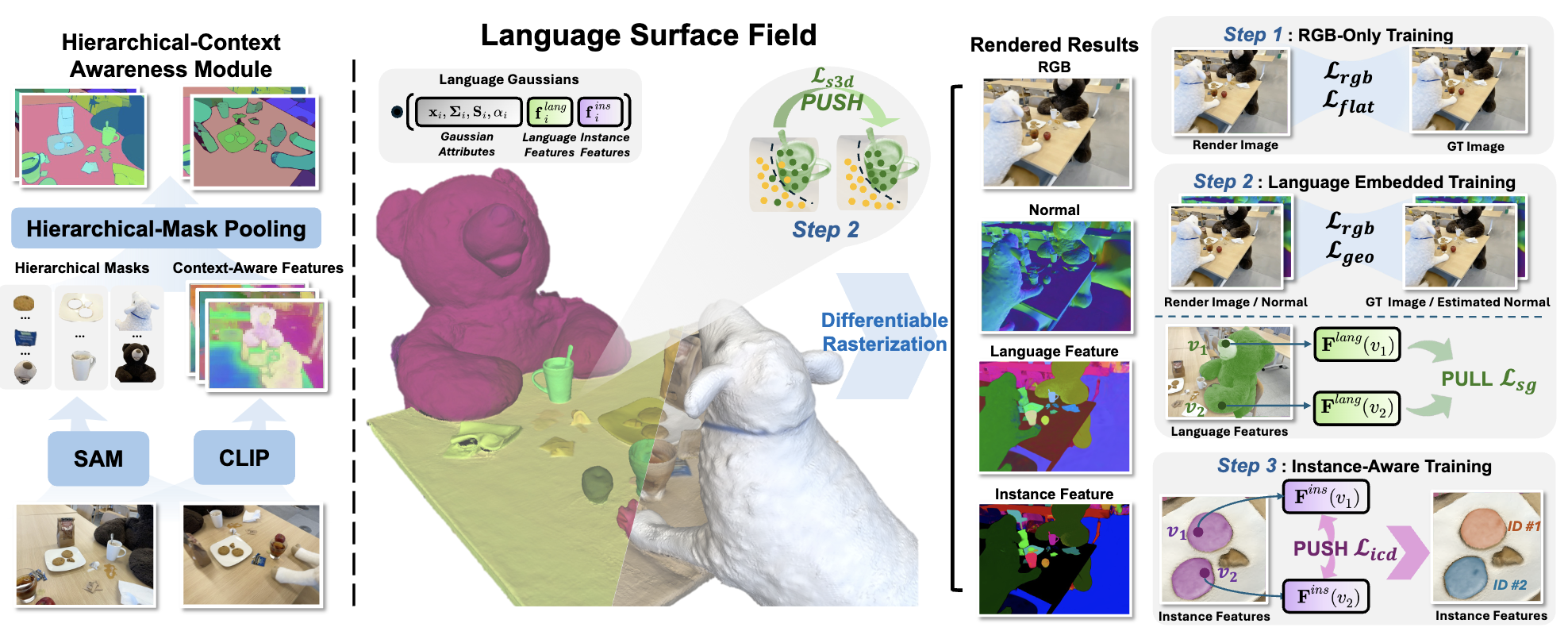
LangSurf: Language-Embedded Surface Gaussians for 3D Scene Understanding
Hao Li*, Minghan Qin*†, Zhengyu Zou*, Diqi He, Bohan Li, Bingquan Dai, Dingwen Zhang†, Junwei Han
- We propose LangSurf, a model that aligns language features with object surfaces to enhance 3D scene understanding
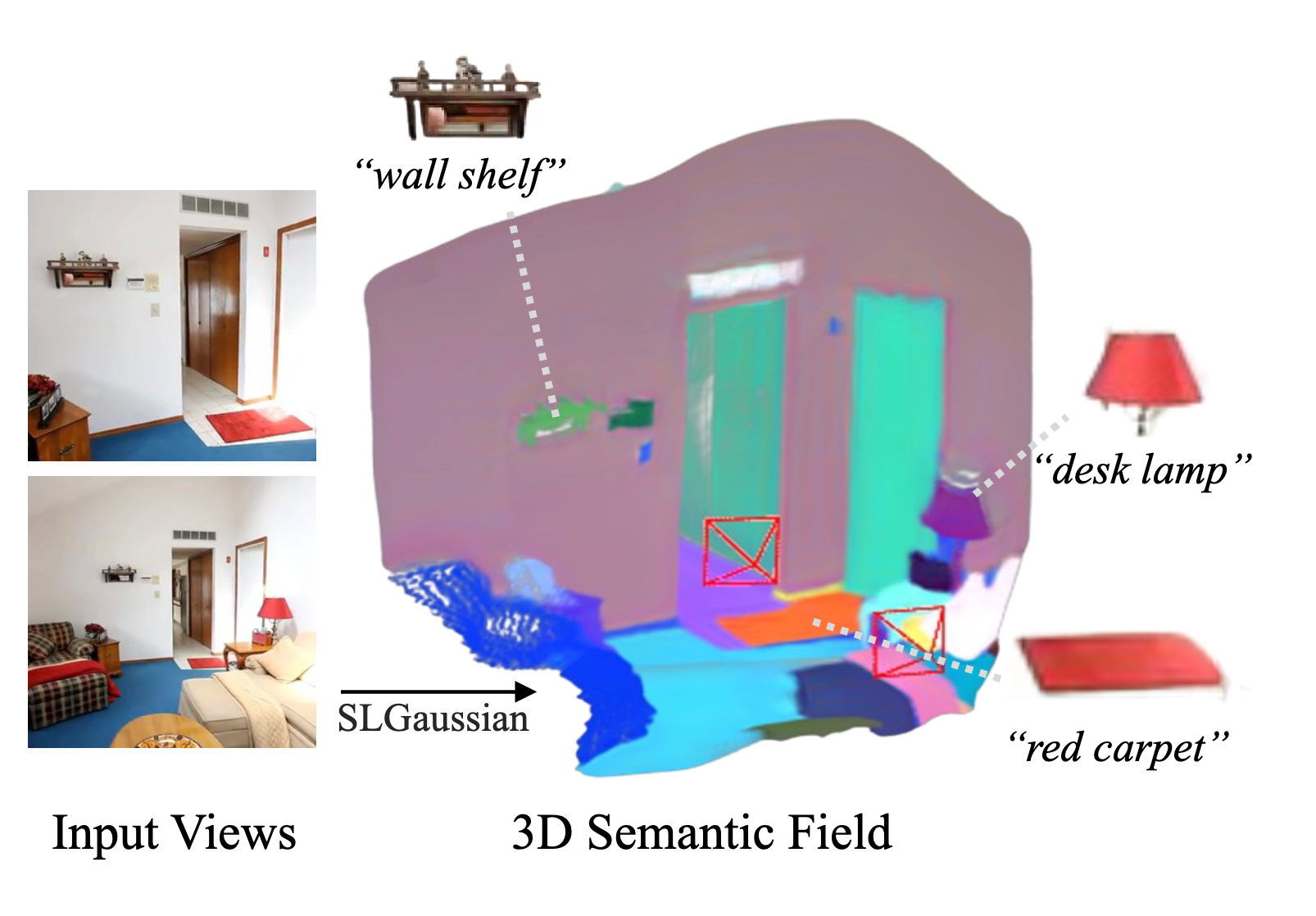
SLGaussian: Fast Language Gaussian Splatting in Sparse Views
Kangjie Chen*, Bingquan Dai*, Minghan Qin, Dongbin Zhang, Peihao Li, Yingshuang Zou, Haoqian Wang†
- We propose SLGaussian, a feed-forward method for constructing 3D semantic fields from sparse viewpoints, allowing direct inference of 3DGS-based scenes.
Generation Model

MeshCoder: LLM-Powered Structured Mesh Code Generation from Point Clouds
Bingquan Dai*, Li Ray Luo*, Qihong Tang, Jie Wang, Xinyu Lian, Hao Xu, Minghan Qin, Xudong Xu, Bo Dai, Haoqian Wang†, Zhaoyang Lyu†, Jiangmiao Pang
- MeshCoder generates structured mesh code from 3D point clouds, enhancing shape editing and understanding.
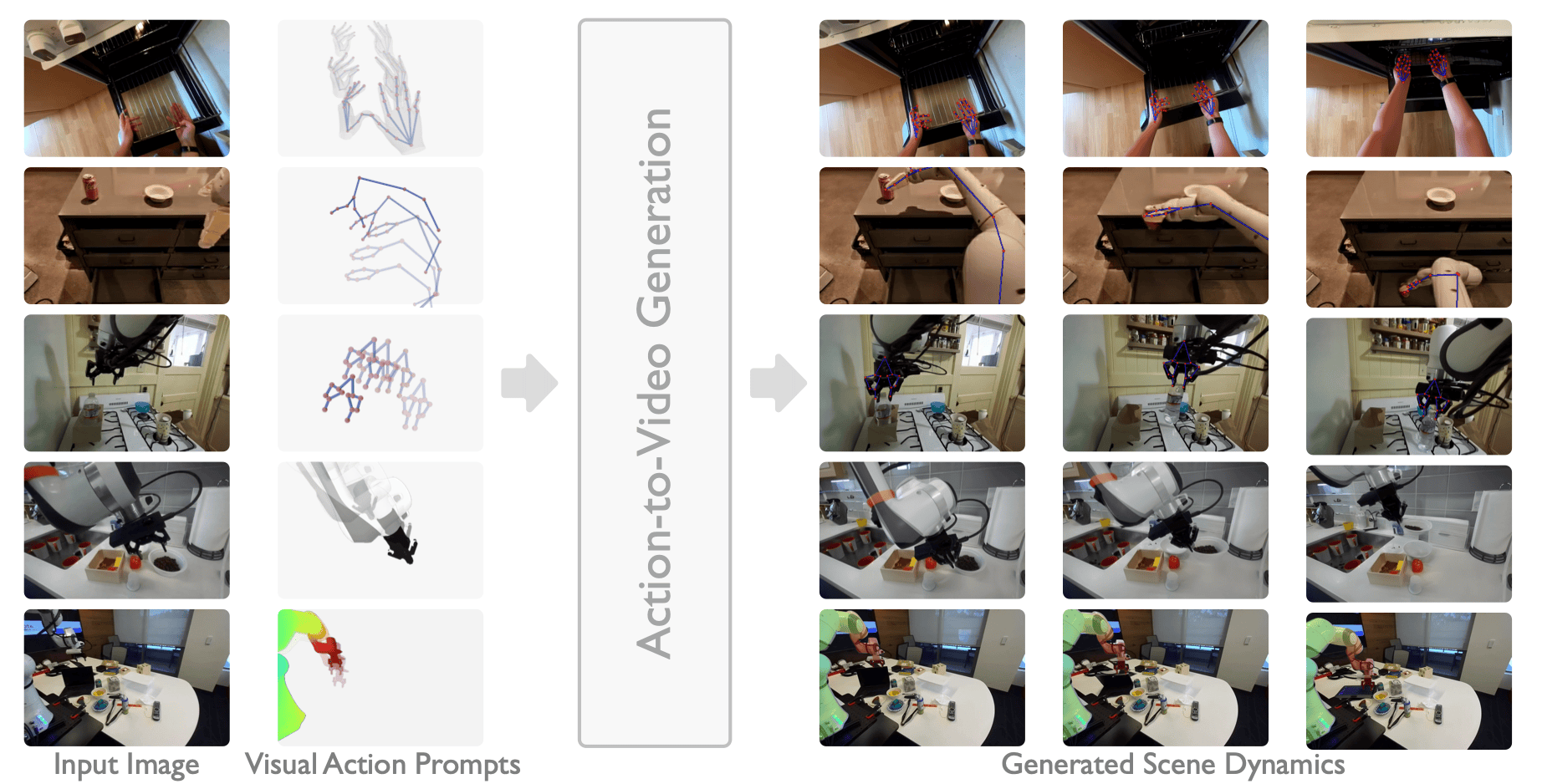
VAP: Precise Action-to-Video Generation through Visual Action Prompts
Yuang Wang, Chao Wen, Haoyu Guo, Sida Peng, Minghan Qin, Hujun Bao, Xiaowei Zhou, Ruizhen Hu
- VAP harnesses subject renderings as action proxies for interactive video generation, striking an balance between precision and generality in action representation.

NOVA3D: Normal Aligned Video Diffusion Model for Single Image to 3D Generation
Yuxiao Yang, Peihao Li, Yuhong Zhang, Junzhe Lu, Xianglong He, Minghan Qin, Weitao Wang, Haoqian Wang†
- NOVA3D unleashes geometric 3D prior from a video diffusion model to generate high-quality textured meshes from input image.
Digital Human

GUAVA: Generalizable Upper Body 3D Gaussian Avatar
Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Yang Li, Minghan Qin, Yu Li, Haoqian Wang
- For each single image with a tracked pose, GUAVA can reconstruct a 3D upper-body Gaussian avatar via feed-forward inference within sub-second time, enabling real-time expressive animation and novel view synthesis at 512✖️512 resolution.
HRAvatar: High-Quality and Relightable Gaussian Head Avatar
Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Kangjie Chen, Minghan Qin, Yu Li†, Haoqian Wang†
- With monocular video input, HRAvatar reconstructs a high-quality, animatable 3D head avatar that enables realistic relighting effects and simple material editing.

Animatable 3d gaussian: Fast and high-quality reconstruction of multiple human avatars
Yang Liu, Xiang Huang, Minghan Qin, Qinwei Lin, Haoqian Wang (* indicates equal contribution)

- We propose Animatable 3D Gaussian, a novel neural representation for fast and high-fidelity reconstruction of multiple animatable human avatars, which can animate and render the model at interactive rate.
Minghan Qin*, Yifan Liu*, Yuelang Xu, Xiaochen Zhao, Yebin Liu†, Haoqian Wang†
- We introduce a novel Spatially-Varying Expression (SVE) conditioning, encompassing both spatial positional features and global expression information.
3D Reconstruction

Quantifying and Alleviating Co-Adaptation in Sparse-View 3D Gaussian Splatting
Kangjie Chen, Yingji Zhong, Zhihao Li, Jiaqi Lin, Youyu Chen, Minghan Qin, Haoqian Wang†

- This paper introduces the concept of co-adaptation in 3D Gaussian Splatting, analyzes its impact on rendering artifacts, and proposes strategies (Dropout Regularization & Opacity Noise Injection) to reduce it.

HDR-GS: Efficient High Dynamic Range Novel View Synthesis at 1000x Speed via Gaussian Splatting
Yuanhao Cai , Zihao Xiao, Yixun Liang, Minghan Qin, Yulun Zhang, Xiaokang Yang, Yaoyao Liu, Alan Yuille

- This paper presents HDR-GS, a novel 3D Gaussian splatting-based method for high dynamic range imaging that achieves 1000x speedup over existing methods.

Gaussian in the Wild: 3D Gaussian Splatting for Unconstrained Image Collections
Dongbin Zhang*, Chuming Wang*, Weitao Wang, Peihao Li, Minghan Qin, Haoqian Wang†

- We utilize 3D Gaussian Splatting with introduced separated intrinsic and dynamic appearance to reconstruct scenes from uncontrolled images, achieving high-quality results and a 1000 × rendering speed increase.

Category-level Object Detection, Pose Estimation and Reconstruction from Stereo Images
Chuanrui Zhang*, Yonggen Ling*†, Minglei Lu, Minghan Qin, Haoqian Wang†
- We present CODERS, a one-stage approach for Category-level Object Detection, pose Estimation and Reconstruction from Stereo images.
🎖 Honors and Awards
- Winner of CVPR 2025 Workshop on Photorealistic 3D Head Avatars (P3HA) Train Viewpoint Track.
- Scholarship, Tsinghua University, 2023.
- National 1st Award, the 10th BD-CASTIC, 2019.
💻 Research Experience
- 2023 - 2024, Harvard University - VCG Lab - Computer Vision Group. I spent a good time with Wanhua Li and Prof. Hanspeter Pfister.
💁 Academic Service
Reviewers of: CVPR, ECCV, ICCV, NeurIPS, SIGGRAPH, ACM MM, AAAI, 3DV, etc.